

自動車の標識認識機能が、ラーメンチェーン天下一品のロゴを「車両進入禁止」の道路標識に誤認する問題。自動車メーカー各社は力を入れていないのか、一向に解決する気配がない。
しかし、この問題に終止符を打つ技術が登場した。自動運転スタートアップTuringが開発を進めるマルチモーダルAI「Heron(ヘロン)」だ。
Heronはどのようにして天下一品問題を解決に導くのか。その概要とともに、Turingの取り組みを振り返っていく。
記事の目次
| 編集部おすすめサービス<PR> | |
| 自動車保険 スクエアbang!(一括見積もり) 「最も安い」自動車保険を選べる!見直すなら今! |  |
| 新車定額!リースナブル(車のカーリース) お好きな車が月1万円台!頭金・初期費用なし! | |
| 車業界への転職はパソナで!(転職エージェント) 転職後の平均年収837〜1,015万円!今すぐ無料登録を | |
| タクシーアプリは「DiDi」(配車アプリ) クーポン超充実!「無料」のチャンスも! | |
| 編集部おすすめサービス<PR> | |
| スクエアbang! |  |
| 「最も安い」自動車保険を提案! | |
| リースナブル | |
| 新車が月々2万円から! | |
| パソナキャリア | |
| 転職後の平均年収837〜1,015万円 | |
| タクシーアプリDiDi | |
| クーポンが充実!「乗車無料」チャンス | |
■マルチモーダル生成AI「Heron」の概要
資格情報を言語化し高度な文脈を理解可能に
Turingは、視覚情報によって得られた情報を人間のように言語化して高度な文脈を理解可能にするAIモデルの開発を進めており、そこで誕生したのがマルチモーダル生成AI「Heron」だ。
日本語を含む複数言語に対応した大規模マルチモーダル学習ライブラリで、画像認識モデルと大規模言語モデルを接続して各モジュールを追加学習するための学習コード、日本語を含むデータセット、最大700億パラメータの学習済みのモデル群で構成されている。
橋渡しを担うアダプタ部分を学習した後、画像エンコーダと大規模言語モデルを追加学習することで、全体として画像に写っているかモノが何かを正確に把握しながら、豊富な言語モデルの知識を利用して回答することが可能になるという。
Heronの学習用ライブラリは、学習する大規模言語モデルを自由に変換可能で、既存言語モデルの性能を生かしつつ、今後開発・公開される新たな大規模言語モデルに対しても容易に対応できる柔軟性を有しているという。
本格的にマルチモーダルモデルを学習するために系統的に学習できるよう工夫されており、ソースコード部分については研究・商用利用が可能な「Apache License 2.0」で公開している。
▼自動運転EV開発のチューリング、日英言語対応のマルチモーダル学習ライブラリ「Heron」と最大700億パラメータの大規模モデル群を公開|Turing
https://tur.ing/posts/n7UT9tmK
複合的な「画像-言語タスク」においてより細やかな文章生成を可能にする
Turingによると、近年注目度が一気に高まった大規模言語モデル(LLM)は、大量のテキストデータを学習に用いることで広い知識の獲得や人間のような応答が可能になる一方、一般的にその入出力はテキストに限定されるため、画像などの視覚情報を用いたタスクには直接適用できないという課題があった。
一方、自動運転においては、カメラなどのセンサーが取得したデータから周囲の車両や歩行者、街路樹、道路標識といったさまざまなオブジェクトを識別し、安全に自律走行できるようAIが判断を下す。
基本的には、各オブジェクトを個別に物体として認識し、連動する前後の画像から「歩行者はこう動く」といった予測を立てて自車をどう制御すべきか判断する。そこに複雑な文脈への理解はない。あらかじめ学習した知見をもとに、シチュエーションごとにシンプルな判断を下すことに留まるのだ。
例えば、道路工事現場の手前に人が立っていたとする。その人がブルー系の作業服を着込み、ヘルメットや安全ベストを装備し誘導灯を手にしていれば、普通のドライバーは警備員と判断し、その指示に従う。
しかし、そこに立っている人がカチッとしたスーツ姿で手に棒状のものを持っていた場合、道路工事との因果関係は不明で警備員とは判断しないのが一般的だ。人間は、これまでに培ってきた知識や経験則をもとに自然に状況を総合的に把握し、判断することができる。
しかし、一般的な自動運転システムの場合、こうした判断が難しい。パーセプション技術により特徴ある格好をした人を識別しても、それが警備員かどうか、先の道路工事と関係があるのか、指示に従うべきかどうかを判断するのは容易ではないのだ。
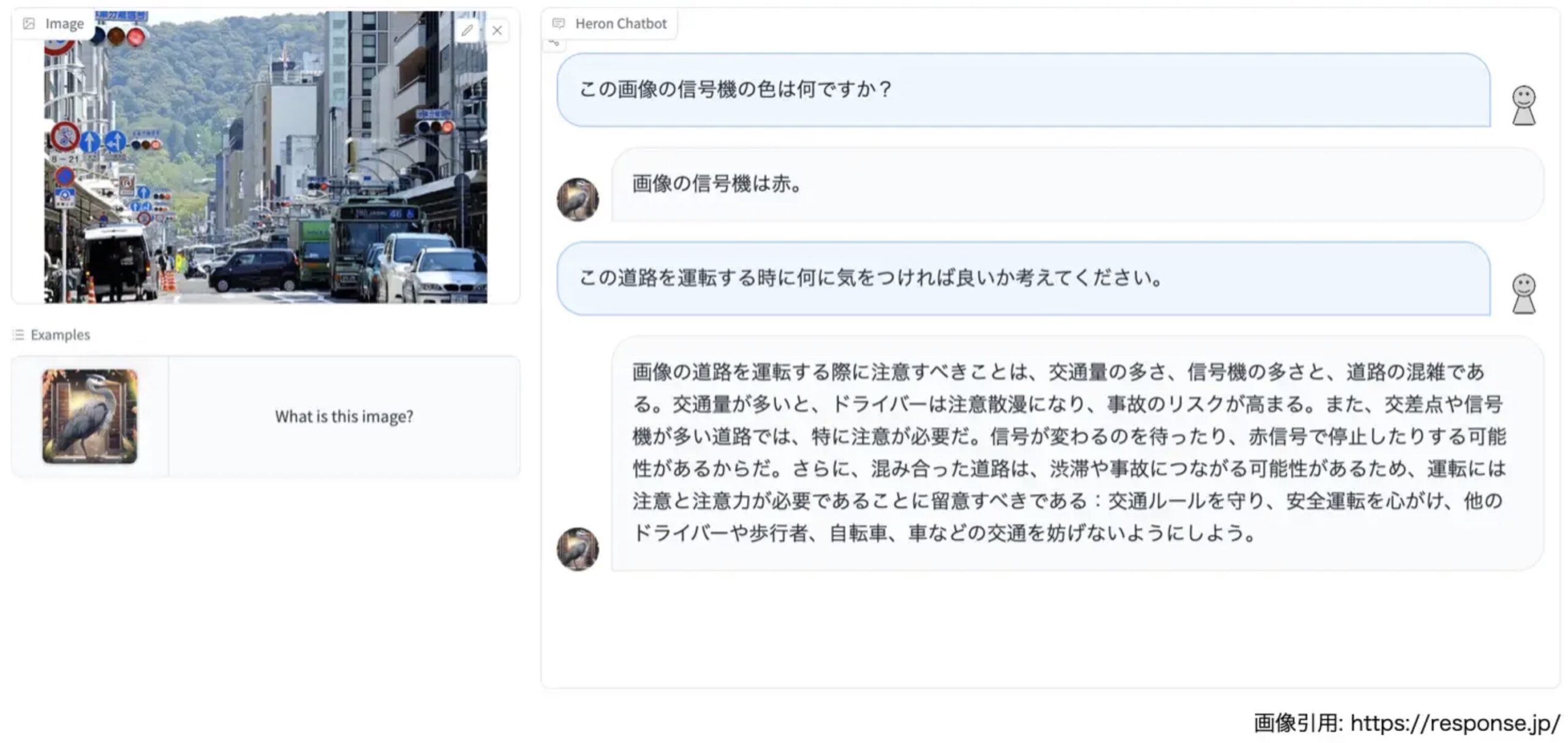
そこでHeronの登場だ。Heronでは、対話を含むデータセットを用いることで自然かつ適切な対話を可能とし、これまでのマルチモーダルモデルでは単純な回答しかできなかった複合的な「画像-言語タスク」においてより詳細で自然な文章生成を行い、前の質問を含む文脈を理解して応答することを可能にする。
ざっくりと言い換えると、その画像に含まれる複数の情報を結びつけ、文脈立てて状況を理解することが可能になるのだ。
シチュエーションから道路標識とラーメン屋の看板を識別
表題の天下一品のロゴ誤認識問題に関しては、同社でAI開発ディレクターを務める山口祐氏がSNS「X」で言及している。山口氏は2023年9月、「先日公開したHeron、何がすごいかって「進入禁止」と「天下一品」を区別できるんですよね」とポストした。
先日公開したHeron、何がすごいかって「進入禁止」と「天下一品」を区別できるんですよねhttps://t.co/zuvAxNWjha pic.twitter.com/t8LfDvvzir
— Yu Yamaguchi | Turing Inc. (@ymg_aq) September 10, 2023
続けて「これは人間にはとても簡単なんですが、通常の画像認識モデルだとかなり難解なタスクです。Heronは画像と言語の複合モデルなので、周辺の意味情報も踏まえた上で、これがラーメン屋の看板だと理解できるわけです」としている。
単純なパーセプション技術では、企業ロゴか道路標識かの判別が難しく、ADASレベルの機能ではシチュエーションに関係なく「道路標識のようなもの」を検知すれば一律にドライバーに通知するものが多い。
しかし、自動運転においてはこうしたあいまいな対処は厳禁だ。厳格に両者を判別できることが望ましいが、そのマークが設置されている場所や設置方法などをもとに類推し、区別する手法も重要だ。こうした技術はさまざまな場面に応用でき、自動運転の質を大幅に引き上げることができる。
【参考】天下一品のロゴ誤認識については「天下一品のロゴ、ホンダ車が「進入禁止」と誤認識 ローソンのフェアで再び・・・」も参照。
■Turingの取り組み
レベル5のEV量産化が目標
Turingは、将棋名人を倒したAI「Ponanza」の開発者として知られる山本一成氏(CEO)と、カーネギーメロン大学などで自動運転開発に関する見識を深めてきた青木俊介氏(CTO)を中心に2021年8月に設立されたスタートアップだ。
高度なAI技術を武器に「We overtake Tesla(テスラを越える)」を目標に掲げ、2030年までに自動運転レベル5相当の完全自動運転EVの量産化を目指している。
2023年3月に自動運転に向けた国産LLM開発に着手したと発表し、以下に焦点を当てたLLM開発を進めていくこととしている。
- ①現実世界への適応力
- ②リアルタイム性と計算効率
- ③安全性と堅牢性
HeronをはじめTerraやCoVLA Datasetなどの開発も
生成AIに関しては、自動運転における「脳」が、人間社会の理解に基づいてロングテールな状況でも柔軟に判断できる能力を与える役割を担う重要な要素と位置づけ、マルチモーダル生成AI「Heron」をはじめ、生成世界モデル「Terra」、自動運転向けVLAモデルデータセット「CoVLA Dataset」などの開発を進め、人間のような深い知識や柔軟な判断能力を持つ完全自動運転の実現を目指している。
Terraは、現実世界の物理法則や物体間の相互作用など複雑な状況を理解し、リアルな運転シーンを動画として出力することが可能な生成世界モデルだ。
アクセルやブレーキ、ステアリングといった詳細な運転操作情報を含むTuring独自の走行データと、オンラインで公開されている走行映像計約1,500時間分のデータを学習に使用し、任意の運転操作を高精度で再現することを可能にしている。
シミュレータとしての利用が可能なほか、自動運転システムの一要素としての利用も可能という。
CoVLA Datasetは、車載センサーデータを含む80時間以上の運転データで構成された日本初の自動運転向けVLA(Vision-Language-Action)モデルデータセットで、データ処理からキャプション生成まで自動化したスケーラブルな手法で構築している。
同データセットを用いて開発したVLAモデル「CoVLA-Agent」は、画像から得た運転環境を自然言語で詳細に説明し、適切な経路計画を生成することが可能という。
レベル5へのアプローチ
同社のテックブログによると、レベル5実現のカギは「知能」にあるとしている。これまで世界で進められてきた自動運転開発においては、LiDARやレーダー、カメラなどのセンサーによる認識技術は高いレベルで実現されており、GPSや高精度マップを組み合わせることで限定区域におけるレベル4完全自動運転は実現されている。
しかし、レベル5では走行したことのない道路や一時的な交通整理、首都高速での合流などハイコンテキストな状況で車同士のコミュニケーションが必要となる運転もできなければならず、こうした複雑な状況を理解し適切に運転するための「知能」が必要としている。
そこでTuringは、「4つの機能、3つの学習、2つのモデル、1つのシステム」 という思想を掲げレベル5開発に取り組んでいるという。
自動運転に必要とされる4つの機能として①解釈②想像③決断④交渉――を定め、マルチモーダル学習やVision and languageの学習、強化学習の3つの学習が必要としている。
これを実現するためには、センサーを中心とした認知・推論を高速に行うモデル「driver」と、総合的な認知・意思決定を行う大規模モデル「navigator」を実装する必要があり、最後にこのdriverとnavigatorを機能させ正しく車を制御できる一つのシステムがTuringが考える完全自動運転システムという。
2025年中に都内30分間自動運転を目指す
Turingは2024年10月、NTTドコモグループの協力のもと、完全自動運転を実現するための専用計算基盤「Gaggle Cluster(ガグルクラスター)」の構築を完了し、運用開始したと発表した。
Gaggle Clusterは、96基のNVIDIA H100 GPUを搭載したTuringの専用計算基盤で、NVIDIA InfiniBand/NDR400を用いたネットワークにより、大規模AI学習において複数のGPUを同時使用する際にボトルネックとなっていたサーバー間の通信速度の制約を最小化しているほか、All-Flash分散ストレージを採用することで分散学習における性能を最大限に引き出し、クラスタ全体を「単一の計算機」として大規模な深層学習タスクに最適化したという。
このGaggle Clusterの活用により独自の自動運転AI「TD-1」を開発し、走行試験を開始したことも発表している。
Turingは2025年12月に人間の介入なしで都内を30分間走行できる自動運転システムを開発するプロジェクト「Tokyo30」を進めている。このプロジェクトに向けた自動運転AIがTD-1で、カメラ映像のみで周辺地図や車両・歩行者の認識、自身の運転操作までを単一モデルで出力するTransformerモデルという。
レベル5実現に向けた取り組みがどんどん具体化している印象だ。
【参考】Turingについては「Turing、完全自動運転EV「2030年10,000台」宣言 半導体チップも製造へ」も参照。
■【まとめ】自動運転分野においては早々にテスラ越えも?
走行エリアが限られたレベル4が「狭く深い」開発を進めるのに対し、レベル5は「広く深い」開発が求められる。その広さは実質的に無限のため、AI自身がさまざまなシチュエーションに柔軟に対応できるようにならなければならない。
言わば、AIをどこまで人間に近づけることができるかが試されており、Turingはそこに向けて邁進しているのだ。
テスラは2025年中にFSDの自動運転化を実現すると発表しているが、Turingのプロジェクト(Tokyo30)の結果次第では、自動運転開発においては早くもテスラに追い付き、追い越す可能性も出てきたように感じる。
開発速度が著しい同社の動向に引き続き注目したい。
【参考】関連記事としては「車が「誤認識しやすいロゴ」、ランキング1位は?事例など踏まえ独自分析」も参照。






するなら?おすすめを口コミ情報から比較【2026年最新】")
の意味・読み方は?自動車業界の新潮流を示す")
ができる車種・機能一覧【トヨタ・ホンダ・日産・スバル】欧米車種も")

