

ルールベースからエンドツーエンドモデルへの移行が進む自動運転開発分野。高精度3次元地図などのデジタルインフラに頼らず、リアルタイムのセンサーデータをベースに状況を判断し、自律走行を行う。
そのためには、桁違いとも言える膨大なデータを常時処理する必要があり、高性能なコンピューティング能力や通信能力、高速ストレージなどハイスペックな環境が必須となる。NVIDIAが自動運転業界を席捲しているのはこのためだ。
しかし、処理すべきデータ量は増加の一途をたどっており、ハードウェアや通信環境を常に圧迫している。そのデータ量はすでにペタバイト級に達しているといい、フリートが多ければ多いほどその量はさらに増加する。処理や保存にも限界があるのではないか。
そこで注目されるのが、データ圧縮技術だ。認識に必要な品質を維持しつつ物理的なデータ量を抑えることで、処理能力などに余裕を持たせることが可能になる。今後、このデータ圧縮技術が自動運転分野で大きなビジネスとなっていくことが予想される。
自動運転×データ圧縮の必要性と動向について解説していく。
記事の目次
| 編集部おすすめサービス<PR> | |
| 自動車保険 スクエアbang!(一括見積もり) 「最も安い」自動車保険を選べる!見直すなら今! |  |
| 新車定額!リースナブル(車のカーリース) お好きな車が月1万円台!頭金・初期費用なし! | |
| 車業界への転職はパソナで!(転職エージェント) 転職後の平均年収837〜1,015万円!今すぐ無料登録を | |
| タクシーアプリは「DiDi」(配車アプリ) クーポン超充実!「無料」のチャンスも! | |
| 編集部おすすめサービス<PR> | |
| スクエアbang! |  |
| 「最も安い」自動車保険を提案! | |
| リースナブル | |
| 新車が月々2万円から! | |
| パソナキャリア | |
| 転職後の平均年収837〜1,015万円 | |
| タクシーアプリDiDi | |
| クーポンが充実!「乗車無料」チャンス | |
■自動運転×データ圧縮の必要性
自動運転開発に走行データは必須
自動運転車の開発には、膨大な量の走行データが欠かせない。ルールベースであれエンドツーエンドであれ、実際の道路をあらゆる環境下で走行したデータがなければコンピュータ・AIに学習させることはできない。道路交通におけるあらゆるシチュエーションを網羅した学習材料が必須なのだ。
道路交通は、同じスポットでも時間帯や天候、季節などで毎回表情を変える。歩行者や他の車両など、周囲の交通参加者の状況も当然異なる。あらゆる状況を学習するためには、何度も何度も走行を繰り返し、無限とも言えるデータを収集して学習に学習を重ねていかなければならないのだ。
この膨大なデータは、基本的に使い捨てることはなく、蓄積していくことになるが、データが増えれば増えるほど保存・管理に要するコストが上がっていくことは言うまでもない。
単純なドラレコ映像は、フルHD画質で1時間当たり6ギガバイトのデータ量となるが、より高精細なカメラ映像に加工データを付加することを考えれば、そのデータ量は倍増どころの話ではなくなる。
自動運転車には複数台のカメラやLiDARなどが搭載
自動運転車には通常、複数台のカメラが搭載されている。WaymoなどはさらにLiDARなど複数のセンサーを搭載している。こうした点を加味すれば、自動運転車1台が生成するデータ量は、数テラバイト級となる。年間では、1ペタバイトに達することも珍しくないようだ。
Waymoのように数千台のフリートを抱えている企業であれば、年間数百ペタバイトどころか、数千ペタバイトに達している可能性も考えられる。なお、100ペタバイトをギガバイトに換算すると、1億ギガバイトとなる。データの一般用途では想像し難い数字だ。もちろん、Waymoクラスであれば、自前のデータ圧縮技術を活用したり、データの取捨選択を行ったりしているものと思われるが、他の開発企業も、事業の拡大とともにこうした状況下に身を置かなければならなくなる。
データ総量をいかに減らすか――という観点で見れば、生成するデータそのものをいかにシンプルなものとするか……などさまざまな手法が考えられるが、そのうちの有効な手段の一つがデータ圧縮技術だ。
YouTubeなどにアップされている動画でも、多くの場合、解像度やビットレートを下げるなどデータ圧縮は当たり前のように行われているものと思われる。重要なのは、圧縮に伴ってデータ品質が著しく落ちていないか――だ。
データを圧縮してサイズを小さくすること自体は難しいことではないが、それに伴って著しく解像度が下がり、オブジェクトの検出など認識精度を損なっては元も子もない。いかにデータ品質を維持しつつ、データ量を圧縮するかが求められるのだ。
最初から効率的なデータが出力されるのが理想?
理想は、保存時のデータ圧縮ではなく、リアルタイムで利用する際の圧縮だ。リアルタイムの映像をコンピュータが解析して自動運転を行う際、そのデータが効率的な処理に適した形で圧縮されていた方が解析時の負荷を小さく抑えられる。
リアルタイム性を損なうことなく、効率的で品質の高いデータをいかに生み出すか。センサー側のソフトウェアもまだまだ改良の余地がありそうだ。
【参考】関連記事「1日1台767TB!?自動運転車のデータ処理で「驚愕の数字」」も参照。
■開発企業の動向
Beamr Imagingが自動運転向けソリューションの展開を開始
映像圧縮技術を有するイスラエルのBeamr Imaging(ビーマー・イメージング)は、同技術を武器に自動運転市場に新規参入した一社だ。
データ圧縮に関する53件の国際特許を取得しており、メディア・エンターテインメント分野を中心に、ライブやVODビデオサービスにおいて高品質かつ高パフォーマンス、比類のないビットレート効率を実現するビデオエンコード、トランスコーディング、最適化ソフトウェアソリューションを提供している。
ハリウッドのスタジオや世界最大級の OTT ストリーミングサービスが導入しており、CABRテクノロジーとソフトウェアエンコーディングのイノベーションを活用し、可能な限り低いビットレートで最高のビデオ品質を提供しているという。
この技術を生かした新たなビジネス領域として注目したのが自動運転分野だ。ビーマーは2025年6月、テクノロジーイベント「 Viva Technology 2025」 の一環として催されたNVIDIA GTC Parisで、自律運転車向けに設計した高性能・高品質のビデオ圧縮ソリューションを発表した。
同社によると、自動運転の開発において動画は主要なデータタイプであり、1台の車両から毎日テラバイト単位の動画データが生成されるとしている。ビデオデータストリームの増加に伴い、クラウドストレージや出力、コンピューティング使用量が急増し、支出が増加する。また、膨大なデータセットはMLライフサイクル全体に摩擦を生み出し、トレーニングや推論、分析を遅らせ、インフラストラクチャの効率を低下させるという。
▼ビーマー社、自動運転車向け「ML-Safe」最適化で20〜50%のデータ削減と高精度検知を同時実現
https://www.atpress.ne.jp/news/9240137
1社あたり数十~数百ペタバイトのビデオデータを処理
1社あたり数十ペタバイトから数百ペタバイト規模のビデオデータを処理している。その量は毎年倍増し、自動運転開発におけるビデオデータの重要な役割と圧縮ソリューションの必要性はさらに高まっている。そこに成長機会と大きなビジネスポテンシャルを見出した。
そこで同社の技術が活躍する。NVIDIAアクセラレーテッドコンピューティングを基盤とするビーマーのコンテンツ適応型ビットレート(CABR)テクノロジーは、機械学習や推論に必要な画質と視覚的な忠実度を維持しながら動画サイズを最大50%削減できるという。
自動運転に必須の認識性能を確保しながら最適な圧縮を実現し、大規模な高性能処理を可能にするのだ。同社によると、数百ペタバイトのビデオデータを30%削減するだけで、年間数百万ドルのコストを削減することが可能になるとしている。
ビーマーは今後、パートナーシップを拡大し、メディア・エンターテインメント、自動運転、AIワークフロー全体にわたって成長を続けるパイプラインの構築を進める。
検証済みのユースケースを戦略的契約につなげ、ワークフロー全体にわたり実証段階から実稼働段階へと移行することを目指す。パートナーによる導入拡大と顧客の要件に沿った実稼働対応ソリューションの提供に注力するとしている。
20〜50%のファイルサイズ削減が可能に
ビーマーの日本展開を支援するジャパン・トゥエンティワンによると、ビーマーの自動運転車向け映像データの「ML-Safe」圧縮アプローチにおいて、20〜50%のファイルサイズ削減と、物体検出・物体位置推定・信頼度における高い再現性を示した最新ベンチマーク結果が公表されたという。

CABR技術により、エンコード済みのデータセットに対する再エンコード最適化においても、機械学習モデルの出力と高い一致を保てることを確認したとしている。
一般的な固定パラメータや一律圧縮は、過小圧縮による無駄または過剰圧縮による精度劣化を招き、増大するデータの管理や機械学習に必要な情報保持などの忠実度、モデル進化に耐える再利用性(将来互換性)の点で課題が残るが、ビーマーのCABR技術は、フレーム内容を解析して特徴を保護しながら動的にビット配分することで、機械学習精度とデータ削減の両立を図ることができるという。
NVIDIAが公開した物理AI AVデータセットからランダム抽出した600本の動画でベンチマークテストを行ったところ、ファイルサイズは20~50%の削減を確認した。検出一貫性(平均適合率)は0.96([IoU 0.50–0.95 | area=all | maxDets=100])、位置推定一貫性においては、バウンディングボックス差分の分布は中心化・狭幅で画素レベルの偏差は極小となる結果となった。
信頼度一貫性については、信頼度スコアは高相関を示し、特に0.8以上の高信頼領域で分散が極小、体系的劣化は観測されず、差分は主にランダム要素だった。総合所見として、約20万件の検出オブジェクトにおいて既存エンコード映像と最適化後映像の差異はごく僅少と結論付けている。
Turingも品質保持とデータ圧縮を両立する技術を開発
国内では、自動運転開発スタートアップのTuringが2025年1月、動画や画像の大規模データを効率的に圧縮しつつ高精度に保持できる技術を開発したと発表している。
局所的に重要情報を集約する学習時の工夫と、重要度に応じたデータの割り当てを組み合わせることで、自動運転AIやマルチモーダルAIなどにおける高速かつ高精度なデータ活用を可能にする。
テキストや画像など多様な情報を、AIが処理するための最小単位となるトークンの列に変換し、それらを必要に応じて増減できる仕組み(可変長圧縮)を導入した。これにより、必要な画質や解析精度を維持しながら、データ容量を大幅に削減することが可能になったという。
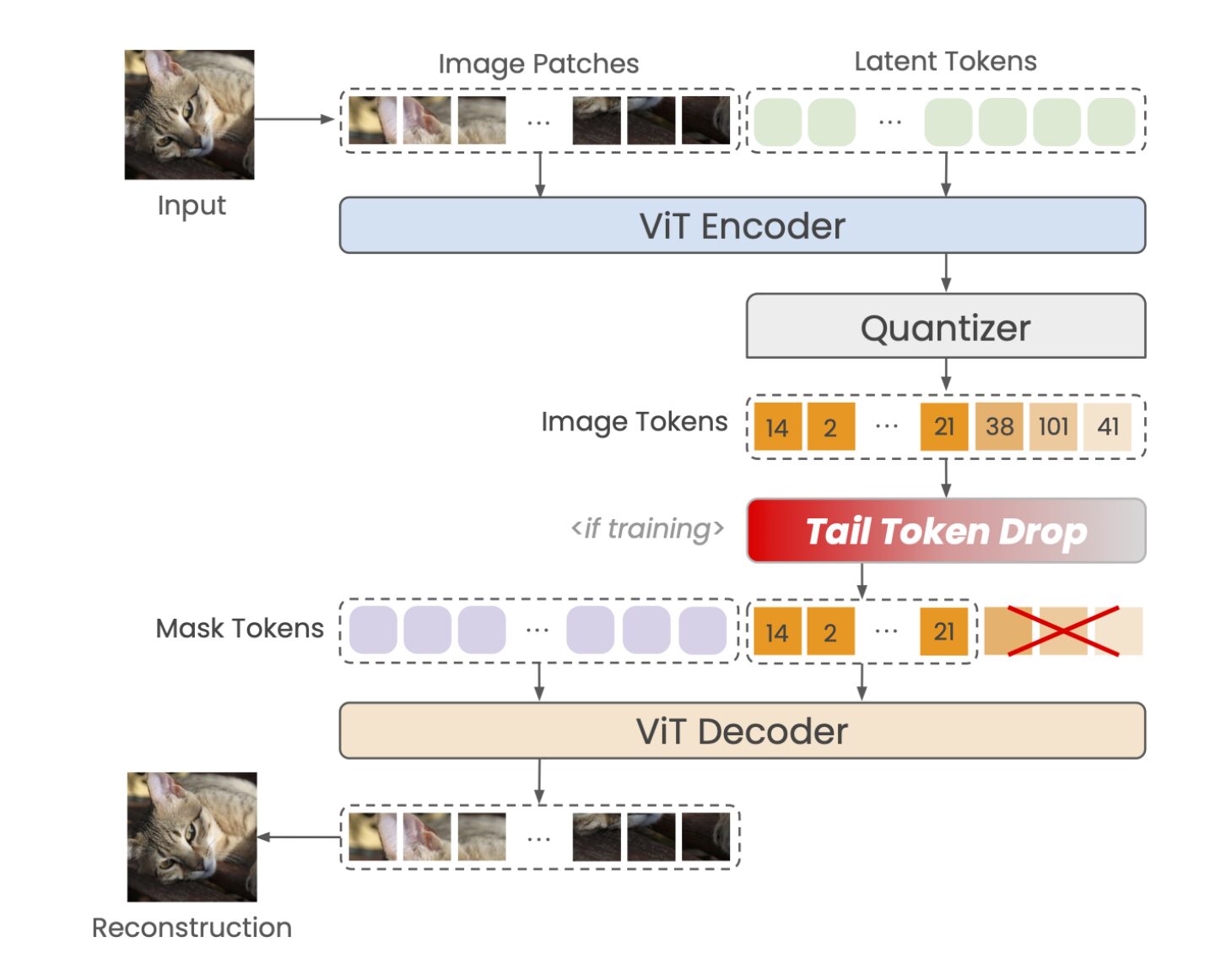
また、学習段階でトークン列の末尾をランダムに削除し、その差異を比較してモデルを最適化する手法「Tail Token Drop」を導入することで、重要情報がデータ列の先頭に集約されるようになっており、これにより圧縮率を高めても肝心な部分を損ないにくい設計を実現した。
同技術ではトークン列から画像を再構成することができ、従来のJPEGやWebPなどの画像フォーマットと比較して小さいバイト数で視覚的に自然な画像を再構成することができる。今後、リアルタイム性や通信コストが特に重要とされる自動運転やクラウド連携システムへの応用が期待できるとしている。
自動運転においては、車載カメラからの映像を少ないトークンに圧縮することで、自動運転基盤モデルに視覚データを効率的に入力することが可能になる。大きなデータを入力した際の計算時間の増大を防ぐことで、大規模AIモデルがリアルタイムで高速に周囲の情報を認識・判断することが可能になる。
▼チューリング、大規模AI向けの視覚データ圧縮技術を開発
https://prtimes.jp/main/html/rd/p/000000061.000098132.html
■【まとめ】新規参入の余地はまだまだ多く残されている
自動運転において、エッジ側とクラウド側でどのように作業・タスクを分担し、効率的なシステムを構築していくかが将来的な課題となるが、現状、開発企業の多くは自動運転システムの開発・強化に全振りしており、データ圧縮にどれだけ目を配ることができているのかは不明だ。
それゆえ、映像系技術やセンサー出力技術など、ビーマーのように専門企業が新規参入してビジネス展開する余地は多く残されているのではないだろうか。異業種からの自動運転業界参入の動きにもしっかりと注目したい。
【参考】関連記事としては「自動運転に必要な技術の現状・課題まとめ AI技術、位置特定・予測技術など」も参照。


とは?搭載する自動車の車種は?自動運転ではない?")




の意味・読み方は?自動車業界の新潮流を示す")
ができる車種・機能一覧【トヨタ・ホンダ・日産・スバル】欧米車種も")

